Problem
The subreddit r/AmITheAsshole has thousands of posts, each judged by the community. Can we predict the post’s outcome (“YTA”, “NTA”, etc.) based only on the title text? This problem presents a classic multi-class text classification task, ideal for exploring tree-based ML models and TF-IDF vectorization.
Dataset
- Preprocessed titles using TF-IDF (5000 features)
- Trained Decision Tree, Random Forest, Bagging, and Gradient Boosting classifiers
- Evaluated using accuracy, F1-score, confusion matrix, and CV scoring
Approach
-
Preprocessing
- Used LabelEncoder to convert outcome labels into numeric classes
- Applied TF-IDF vectorization (max_features=5000) on titles
-
Models Compared
- Decision Tree
- Random Forest
- Gradient Boosting
- Bagging (Base Tree: Depth=5)
Each model was evaluated on:
- Accuracy
- Precision, Recall, F1-Score (Weighted)
- Confusion Matrix
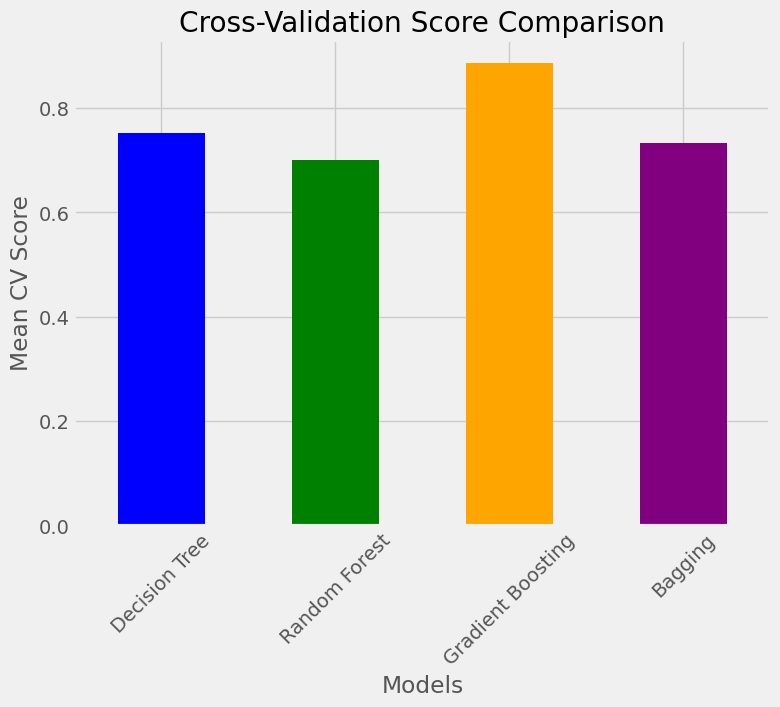
- 5-fold Cross-Validation Score
Results Summary
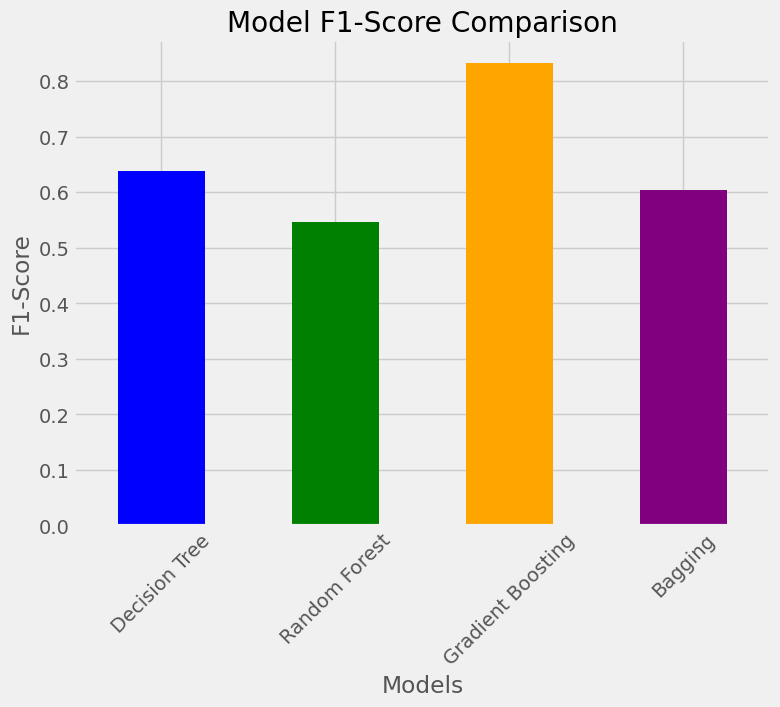
| Model | Accuracy | Precision | Recall | F1-Score | | --------------------- | -------- | --------- | -------- | -------- | | Gradient Boosting | 0.86 | 0.88 | 0.86 | 0.83 | | Decision Tree | 0.72 | 0.74 | 0.72 | 0.64 | | Bagging | 0.70 | 0.76 | 0.70 | 0.60 | | Random Forest | 0.67 | 0.68 | 0.67 | 0.55 |
Code Below
Github https://github.com/kerixyz/pred-aita/blob/main/pred.md
df_big = pd.read_csv('aita7780.csv')
print(df_big.isnull().sum())Unnamed: 0 0 id 0 flair 0 title 0 body 0 dtype: int64
#convert flair (outcome var) to numerical vals
le = LabelEncoder()
df_big['flair_num'] = le.fit_transform(df_big['flair'])Train / Test Split
#split into test / train
X = df_big['title']
y = df_big['flair_num']
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=17)df_big['title'][2]
'AITA for preferring that my uncle teach me to drive than my dad and refusing to tell my dad why?'
tfidf = TfidfVectorizer(max_features=5000)
X_train_tfidf = tfidf.fit_transform(X_train)
X_test_tfidf = tfidf.transform(X_test)dt_model = DecisionTreeClassifier(random_state=17, max_depth=10)
dt_model.fit(X_train_tfidf, y_train)
y_pred_dt = dt_model.predict(X_test_tfidf)
temp = dt_model.fit(X_train_tfidf, y_train)
fig = plt.figure(figsize=(25,20))
_ = tree.plot_tree(temp,
filled=True)print('Decision Tree Accuracy:',accuracy_score(y_test,y_pred_dt))
0.7172236503856041
rf_model = RandomForestClassifier(random_state=17, max_depth=10, n_estimators=100)
rf_model.fit(X_train_tfidf, y_train)
y_pred_rf = rf_model.predict(X_test_tfidf)
print("Random Forest Accuracy:", accuracy_score(y_test, y_pred_rf))Random Forest Accuracy: 0.6735218508997429
base_tree = DecisionTreeClassifier(max_depth=5, random_state=17)
bagging_model = BaggingClassifier(estimator=base_tree, n_estimators=50, random_state=17)
bagging_model.fit(X_train_tfidf, y_train)
y_pred_bagging = bagging_model.predict(X_test_tfidf)
print("Bagging Accuracy:", accuracy_score(y_test, y_pred_bagging))
Bagging Accuracy: 0.7011568123393316
gb_model = GradientBoostingClassifier(random_state=17)
gb_model.fit(X_train_tfidf, y_train)
y_pred_gb = gb_model.predict(X_test_tfidf)
print("Gradient Boosting Accuracy:", accuracy_score(y_test, y_pred_gb))
Gradient Boosting Accuracy: 0.859254498714653
##Collect Merics for Cmparison
def eval_model(model, X_test, y_test):
y_pred = model.predict(X_test)
return{
'Accuracy':accuracy_score(y_test, y_pred),
'Precision': precision_score(y_test,y_pred,average='weighted'),
'Recall':recall_score(y_test,y_pred,average='weighted'),
'F1-Score': f1_score(y_test,y_pred, average='weighted')
}metrics = {
'Decision Tree': eval_model(dt_model, X_test_tfidf,y_test),
'Random Forest': eval_model(rf_model, X_test_tfidf, y_test),
'Gradient Boosting': eval_model(gb_model, X_test_tfidf, y_test),
'Bagging': eval_model(bagging_model, X_test_tfidf, y_test)
}metrics_df = pd.DataFrame(metrics)
print(metrics_df)| Metric | Decision Tree | Random Forest | Gradient Boosting | Bagging | |------------|----------------|----------------|--------------------|-----------| | Accuracy | 0.717224 | 0.673522 | 0.859254 | 0.701157 | | Precision | 0.742257 | 0.682193 | 0.883698 | 0.756093 | | Recall | 0.717224 | 0.673522 | 0.859254 | 0.701157 | | F1-Score | 0.638219 | 0.545953 | 0.832780 | 0.604238 |
metrics_df['Accuracy'].plot(kind='bar', color=['blue', 'green', 'orange', 'purple'], figsize=(8, 6))
plt.style.use('fivethirtyeight')
plt.title('Model Accuracy Comparison')
plt.ylabel('Accuracy')
plt.xlabel('Models')
plt.xticks(rotation=45)
plt.show()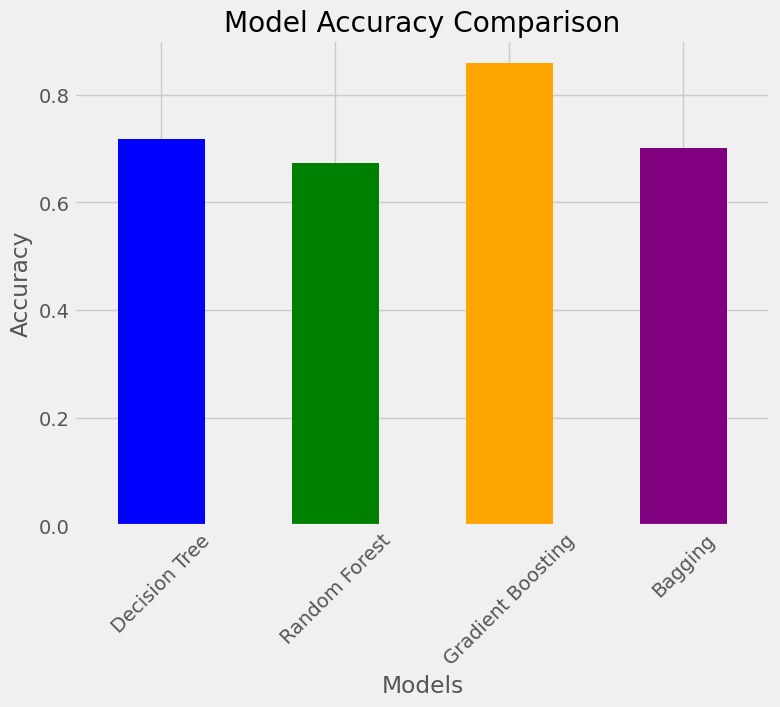
metrics_df['F1-Score'].plot(kind='bar', color=['blue', 'green', 'orange', 'purple'], figsize=(8, 6))
plt.title('Model F1-Score Comparison')
plt.ylabel('F1-Score')
plt.xlabel('Models')
plt.xticks(rotation=45)
plt.show()
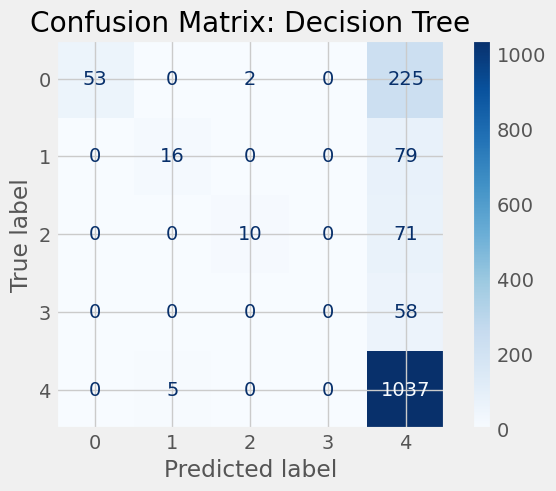
models = [("Decision Tree", dt_model),
("Random Forest", rf_model),
("Gradient Boosting", gb_model),
("Bagging", bagging_model)]
for name, model in models:
disp = ConfusionMatrixDisplay.from_estimator(model, X_test_tfidf, y_test, cmap=plt.cm.Blues)
disp.ax_.set_title(f"Confusion Matrix: {name}")
plt.show()
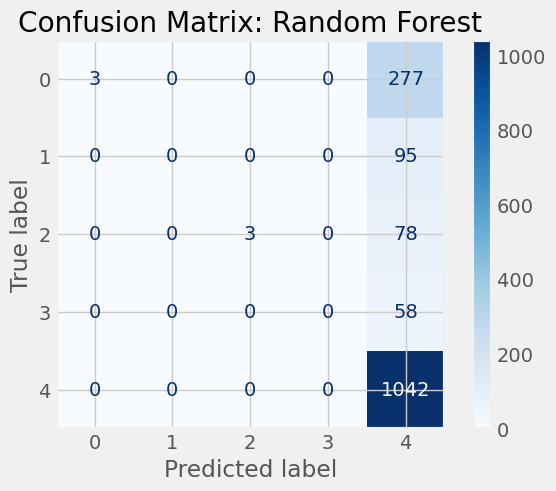
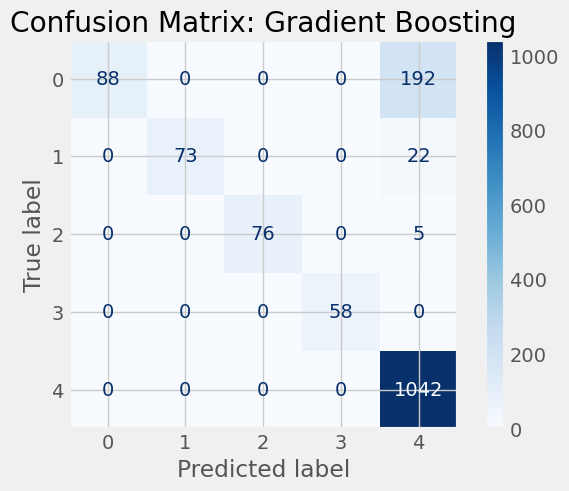
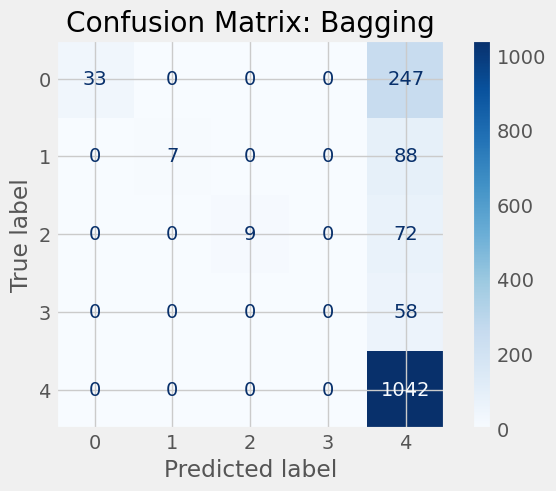
cv_scores = {
"Decision Tree": np.mean(cross_val_score(dt_model, X_train_tfidf, y_train, cv=5)),
"Random Forest": np.mean(cross_val_score(rf_model, X_train_tfidf, y_train, cv=5)),
"Gradient Boosting": np.mean(cross_val_score(gb_model, X_train_tfidf, y_train, cv=5)),
"Bagging": np.mean(cross_val_score(bagging_model, X_train_tfidf, y_train, cv=5))
}cv_scores_series = pd.Series(cv_scores)
cv_scores_series.plot(kind='bar', color=['blue', 'green', 'orange', 'purple'], figsize=(8, 6))
plt.title('Cross-Validation Score Comparison')
plt.ylabel('Mean CV Score')
plt.xlabel('Models')
plt.xticks(rotation=45)
plt.show()